
Hypothesis Testing: The Best Comprehensive Guide
Hypothesis testing is a fundamental concept in statistical analysis, serving as a cornerstone for scientific research and data-driven decision-making. This guide will walk you through the essentials of hypothesis testing, providing practical examples and insights for students and professionals in handling statistical assignments.
Key Takeaways
- Hypothesis testing is a statistical method used to make inferences about population parameters based on sample data.
- The process involves formulating null and alternative hypotheses, choosing a test statistic, and making decisions based on calculated probabilities.
- Common types of hypothesis tests include z-tests, t-tests, chi-square tests, and ANOVA.
- Understanding p-values, significance levels, and types of errors is crucial for correctly interpreting results.
- Hypothesis testing has applications across various fields, including medical research, social sciences, and business.
Introduction to Hypothesis Testing
Hypothesis testing is a statistical method used to make inferences about population parameters based on sample data. It plays a crucial role in scientific research, allowing researchers to draw conclusions about larger populations from limited sample sizes. The process involves formulating and testing hypotheses about population parameters, such as means, proportions, or variances.
What is a Statistical Hypothesis?
A statistical hypothesis is an assumption or statement about a population parameter. In hypothesis testing, we typically work with two hypotheses:
- Null Hypothesis (H0): The default assumption that there is no effect or no difference in the population.
- Alternative Hypothesis (H1 or Ha): The hypothesis that challenges the null hypothesis, suggesting that there is an effect or difference.
Fundamentals of Hypothesis Testing
Understanding the basic concepts of hypothesis testing is essential for correctly applying and interpreting statistical analyses.
Types of Errors in Hypothesis Testing
When conducting hypothesis tests, two types of errors can occur:
| Error Type | Description | Probability |
|---|---|---|
| Type I Error | Rejecting a true null hypothesis | α (alpha) |
| Type II Error | Failing to reject a false null hypothesis | β (beta) |
The significance level (α) is the probability of committing a Type I error, typically set at 0.05 or 0.01. The power of a test (1 – β) is the probability of correctly rejecting a false null hypothesis.
P-values and Statistical Significance
The p-value is a crucial concept in hypothesis testing. It represents the probability of obtaining results at least as extreme as the observed results, assuming the null hypothesis is true. A smaller p-value indicates stronger evidence against the null hypothesis.
Steps in Hypothesis Testing
Hypothesis testing follows a structured process:
- Formulate the hypotheses: State the null (H0) and alternative (H1) hypotheses.
- Choose a test statistic: Select an appropriate test based on the data and research question.
- Determine the critical value and rejection region: Set the significance level and identify the conditions for rejecting H0.
- Calculate the test statistic: Compute the relevant statistic from the sample data.
- Make a decision and interpret results: Compare the test statistic to the critical value or p-value to the significance level.
Example 1
A sample of 100 males with a mean height of 172 cm and a known population standard deviation of 10 cm. Is the average height of adult males in this population different from 170 cm?
Solution
This is a One-Sample Z-Test
Hypotheses:
- H0: μ = 170 cm (The population mean height is 170 cm)
- H1: μ ≠ 170 cm (The population mean height is not 170 cm)
Test Statistic: Z-test (assuming known population standard deviation)
Critical Value: For a two-tailed test at α = 0.05, the critical z-values are ±1.96
Calculation:
[latex] Z=\frac{{\displaystyle\overset-x}-\mu_o}{\displaystyle\frac s{\sqrt n}} [/latex]
[latex] Z=\frac{172-170}{\displaystyle\textstyle\frac{10}{\sqrt{100}}} [/latex] = 2
Decision:
Since |Z| = 2 > 1.96, we reject the null hypothesis.
Interpretation:
There is sufficient evidence to conclude that the average height of adult males in this population is significantly different from 170 cm (p < 0.05).
Example 2
An Oil factory has a machine that dispenses 80mL of oil in a bottle. An employee believes the average amount of oil is not 80mL. Using 40 samples, he measures the average amount dispensed by the machine to be 78mL with a standard deviation of 2.5.
a) State the null and alternative hypotheses.
- H0: μ = 80 mL (The average amount of oil is 80 mL)
- H1: μ ≠ 80 mL (The average amount of oil is 80 mL)
b) At a 95% confidence level, is there enough evidence to support the idea that the machine is not working properly?
Given that H1: μ ≠ 80, we will conduct a two-tail test. Since the confidence level is 95%, this means that in a normal distribution curve, the right and left sides will be represented by 2.5% each, which is 0.025, as shown in the diagram below.
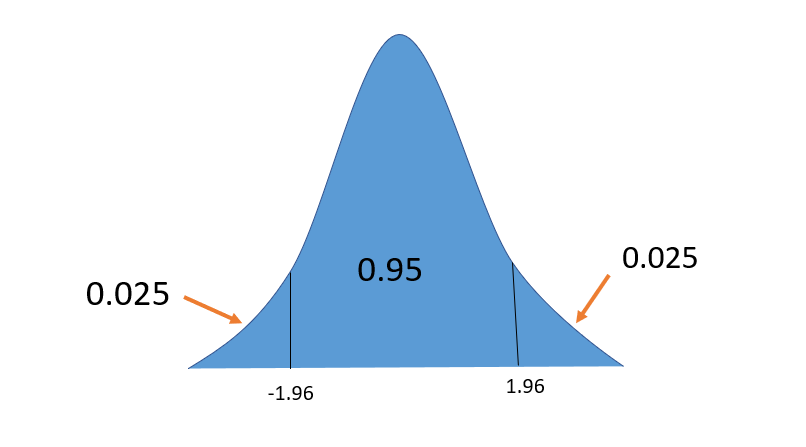
From the Z-score table, the Z-value that corresponds to a 95% confidence level is 1.96.
Now, the critical Z-values = ±1.96
From here, we will calculate the z-value and compare it with the critical z-value to determine if we are rejecting the null hypothesis.
[latex] Z=\frac{{\displaystyle\overset-x}-\mu_o}{\displaystyle\frac s{\sqrt n}} [/latex]
x̄ = 78
S = 2.5
μ0= 80
n = 40
[latex]Z=\frac{78-80}{\displaystyle\textstyle\frac{2.5}{\sqrt{40}}}[/latex]
Z=-5.06
Since |Z| = 5 > 1.96, it implies that it falls in the rejection zone; therefore, we reject the null hypothesis.
Common Hypothesis Tests
Several types of hypothesis tests are commonly used in statistical analysis:
Z-Test
The z-test is used when the population standard deviation is known and the sample size is large (n ≥ 30). It’s suitable for testing hypotheses about population means or proportions.
T-Test
The t-test is similar to the z-test but is used when the population standard deviation is unknown and estimated from the sample. It’s particularly useful for small sample sizes.
Types of t-tests include:
- One-sample t-test
- Independent samples t-test
- Paired samples t-test
Chi-Square Test
The chi-square test is used to analyze categorical data. It can be applied to:
- Test for goodness of fit
- Test for independence between two categorical variables
ANOVA (Analysis of Variance)
ANOVA is used to compare means across three or more groups. It helps determine if there are significant differences between group means. Click here to learn more about ANOVA.
Applications of Hypothesis Testing
Hypothesis testing finds applications across various fields:
Medical Research
In clinical trials, hypothesis tests are used to evaluate the efficacy of new treatments or drugs. For example, researchers might test whether a new medication significantly reduces blood pressure compared to a placebo.
Social Sciences
Social scientists use hypothesis testing to analyze survey data and test theories about human behavior. For instance, a psychologist might test whether there’s a significant difference in stress levels between urban and rural residents.
Business and Economics
In business, hypothesis tests can be used for:
- Quality control processes
- A/B testing in marketing
- Analyzing the impact of economic policies
Interpreting and Reporting Results
When interpreting hypothesis test results, it’s crucial to consider both statistical and practical significance.
Statistical vs. Practical Significance
- Statistical Significance: Indicates that the observed difference is unlikely to occur by chance.
- Practical Significance: Considers whether the observed difference is large enough to be meaningful in real-world applications.
Confidence Intervals
Confidence intervals provide a range of plausible values for a population parameter. They complement hypothesis tests by providing information about the precision of estimates.
| Confidence Level | Z-score |
|---|---|
| 90% | 1.645 |
| 95% | 1.960 |
| 99% | 2.576 |
Limitations and Criticisms
While hypothesis testing is widely used, it’s not without limitations:
- Misinterpretation of p-values: P-values are often misunderstood as the probability that the null hypothesis is true.
- Overreliance on significance thresholds: The arbitrary nature of significance levels (e.g., 0.05) can lead to binary thinking.
- Publication bias: Studies with significant results are more likely to be published, potentially skewing the scientific literature.
Advanced Topics in Hypothesis Testing
As we delve deeper into hypothesis testing, it’s important to explore some more advanced concepts that can enhance your understanding and application of these statistical methods.
Power Analysis
Power analysis is a crucial aspect of experimental design that helps determine the sample size needed to detect a meaningful effect.
Statistical Power is the probability of correctly rejecting a false null hypothesis. It’s calculated as 1 – β, where β is the probability of a Type II error.
Key components of power analysis include:
- Effect size
- Sample size
- Significance level (α)
- Power (1 – β)
| Desired Power | Typical Values |
|---|---|
| Low | 0.60 – 0.70 |
| Medium | 0.70 – 0.80 |
| High | 0.80 – 0.90 |
| Very High | > 0.90 |
Researchers often aim for a power of 0.80, balancing the need for accuracy with practical constraints.
Effect Size
Effect size quantifies the magnitude of the difference between groups or the strength of a relationship between variables. Unlike p-values, effect sizes are independent of sample size and provide information about practical significance.
Common effect size measures include:
- Cohen’s d (for t-tests)
- Pearson’s r (for correlations)
- Odds ratio (for logistic regression)
| Effect Size (Cohen’s d) | Interpretation |
|---|---|
| 0.2 | Small |
| 0.5 | Medium |
| 0.8 | Large |
Bayesian Hypothesis Testing
Bayesian hypothesis testing offers an alternative to traditional frequentist approaches. It incorporates prior beliefs and updates them with observed data to calculate the probability of a hypothesis being true.
Key concepts in Bayesian hypothesis testing include:
- Prior probability
- Likelihood
- Posterior probability
- Bayes factor
The Bayes factor (BF) quantifies the evidence in favor of one hypothesis over another:
| Bayes Factor | Evidence Against H0 |
|---|---|
| 1 – 3 | Weak |
| 3 – 20 | Positive |
| 20 – 150 | Strong |
| > 150 | Very Strong |
Multiple Comparisons Problem
When conducting multiple hypothesis tests simultaneously, the probability of making at least one Type I error increases. This is known as the multiple comparisons problem.
Methods to address this issue include:
- Bonferroni Correction: Adjusts the significance level by dividing α by the number of tests.
- False Discovery Rate (FDR) Control: Focuses on controlling the proportion of false positives among all rejected null hypotheses.
- Holm’s Step-down Procedure: A more powerful alternative to the Bonferroni correction.
Replication Crisis and Open Science
The replication crisis in science has highlighted issues with the traditional use of hypothesis testing:
- P-hacking: Manipulating data or analysis to achieve statistical significance.
- HARKing (Hypothesizing After Results are Known): Presenting post-hoc hypotheses as if they were pre-registered.
- Low statistical power: Many studies are underpowered, leading to unreliable results.
To address these issues, the open science movement promotes:
- Pre-registration of hypotheses and analysis plans
- Sharing of data and code
- Emphasis on effect sizes and confidence intervals
- Replication studies
Conclusion
Hypothesis testing is a powerful tool in statistical analysis, but it requires careful application and interpretation. By understanding both its strengths and limitations, researchers can use hypothesis testing effectively to draw meaningful conclusions from data. Remember that statistical significance doesn’t always imply practical importance and that hypothesis testing is just one part of the broader scientific process. Combining hypothesis tests with effect size estimates, confidence intervals, and thoughtful experimental design will lead to more robust and reliable research findings.
FAQs
What’s the difference between one-tailed and two-tailed tests?
One-tailed tests examine the possibility of a relationship in one direction, while two-tailed tests consider the possibility of a relationship in both directions.
One-tailed test: Used when the alternative hypothesis specifies a direction (e.g., “greater than” or “less than”).
Two-tailed test: Used when the alternative hypothesis doesn’t specify a direction (e.g., “not equal to”).
How do I choose between parametric and non-parametric tests?
The choice depends on your data characteristics:
Parametric tests (e.g., t-test, ANOVA) assume the data follows a specific distribution (usually normal) and work with continuous data.
Non-parametric tests (e.g., Mann-Whitney U, Kruskal-Wallis) don’t assume a specific distribution and are suitable for ordinal or ranked data.
Use non-parametric tests when:
The sample size is small
The data is not normally distributed
The data is ordinal or ranked
What’s the relationship between confidence intervals and hypothesis tests?
Confidence intervals and hypothesis tests are complementary:
If a 95% confidence interval for a parameter doesn’t include the null hypothesis value, the
corresponding two-tailed hypothesis test will reject the null hypothesis at the 0.05 level.
Confidence intervals provide more information about the precision of the estimate and the range of plausible values for the parameter.
What are some alternatives to traditional null hypothesis significance testing?
Estimation methods: Focusing on effect sizes and confidence intervals rather than binary decisions.
Bayesian inference: Using prior probabilities and updating beliefs based on observed data.
Information-theoretic approaches: Using models like the Akaike Information Criterion (AIC) for model selection.
